
jdk 命令
HotSpot JVM中GC的实现主要有以下的几种:
Serial/Serial Old
ParNew
Parallel Scavenge/Parallel Old
Concurrent Mark Sweep(CMS)
Garbage First(G1)
分别简单总结一下。
Serial/Serial Old
Serial 收集器是最基本的、历史最悠久的收集器。从字面上就能看出,这是一个单线程的收集器,即在进行GC时必须STW。
Serial收集器在新生代采用复制算法,在老年代采用标记-清理-压缩算法(Serial Old)。
ParNew
ParNew收集器是Serial收集器的多线程版本,采用多线程进行收集,但一样要STW。
与Serial类似,ParNew收集器在新生代采用复制算法,在老年代采用标记-清理-压缩算法。
ParNew比较重要,因为它可以配合CMS收集器一起使用(Parallel Scavenge则不行)。ParNew是-XX:+UseConcMarkSweepGC选项下默认的新生代收集器。
Parallel Scavenge
Parallel Scavenge是一个新生代收集器,它与ParNew最主要的区别是它的目标是吞吐量优先而不是时间优先(注意这两个不能兼得)。所谓吞吐量就是CPU用于运行用户代码的时间与CPU运行总时间的比值。吞吐量优先适合在后台完成计算而不需要太多交互的业务,而时间优先适合需要交互和实时性的业务。
Parallel Scavenge可以精确控制吞吐量,通过两个参数:控制最大垃圾收集停顿时间的-XX:MaxGCPauseMillis参数及直接设置吞吐量大小的-XX:GCTimeRatio参数。它还可以通过打开-XX:+UseAdaptiveSizePolicy参数进行自适应调节(GC Ergonomics),打开后JVM会根据当前运行状况收集监控信息并动态调整参数来提供最合适的吞吐量,配合前两个参数使用更好。
Parallel Old
Parallel Old是Parallel Scavenge对应的老年代版本,目标也是吞吐量优先,可以与Parallel Scavenge结合。
Concurrent Mark Sweep
CMS是真正意义上的并发收集器,作用于老年代。CMS的目标是时间优先(最短停顿时间),像服务器之类的就很适合跑在CMS收集器下,因为互联网服务重视服务的响应速度,希望系统延迟时间短。CMS通常与ParNew配合使用。
CMS是基于标记-清除算法实现的,整个过程分几步:
初始标记(initial-mark):从GC Root开始,仅扫描与根节点直接关联的对象并标记,这个过程需要STW,但是GC Root数量有限,因此时间较短
并发标记(concurrent-mark):这个阶段在初始标记的基础上继续向下进行遍历标记。这个阶段与用户线程并发执行,因此不停顿
并发预清理(concurrent-preclean):上一阶段执行期间,会出现一些刚刚晋升老年代的对象,该阶段通过重新扫描减少下一阶段的工作。该阶段并发执行,不停顿
重新标记(CMS-remark):重新标记阶段会对CMS堆上的对象进行扫描,以对并发标记阶段遭到破坏的对象引用关系进行修复,以保证执行清理之前对象引用关系是正确的。这一阶段需要STW,时间也比较短暂
并发清理(concurrent-sweep):清理垃圾对象,这个过程与用户线程并发执行,不停顿
并发重置(concurrent-reset):重置CMS收集器的数据结构,等待下一次GC
可以看到,整个过程中需要STW的阶段仅有初始标记和重新标记阶段,所以可以说它的停顿时间比较短(当然吞吐量可能会受影响)。
由于CMS是基于[标记-清理]算法的,因此会产生大量的内存碎片。这很可能会出现老年代虽然有大量不连续的空闲内存,但很难找到连续的内存空间来给对象分配,不得不提前触发一次Full GC的情况。针对这一点,CMS提供了一个-XX:+UseCMSCompactAtFullCollection开关(默认开启),用于在CMS要gg的时候进行内存碎片整理从而得到连续的内存空间。这样内存碎片的问题可以解决,但STW的时间也相应变长。另外,CMS收集器无法处理 浮动垃圾(Floating Garbage),可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。由于CMS并发清理阶段用户线程还在运行着,伴随程序的运行自然还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS无法在本次收集中处理掉它们,只好留待下一次GC时再将其清理掉,这一部分垃圾就称为“浮动垃圾”。由于在垃圾收集阶段用户线程还需要运行,即还需要预留足够的内存空间给用户线程使用,因此CMS收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。在默认设置下,CMS收集器在老年代使用了92%的空间后就会被激活(JDK 1.6)。可以通过设置-XX:CMSInitiatingOccupancyFraction的值来改变这个阈值。注意一定要结合实际的运行情况,不要设的太大,假如内存真的太满,CMS要gg的时候就会临时召唤出Serial Old对老年代进行Full GC,停顿时间长,因此一定要合理设置这个参数的值。
【关于CMS-concurrent-abortable-preclean】:从日志中我们还发现了一个细节叫做CMS-concurrent-abortable-preclean,这就要从Concurrent precleaning阶段说起了。Concurrent precleaning阶段的实际行为是:针对新生代做抽样,等待新生代在某个时间段(默认5秒,可以通过CMSMaxAbortablePrecleanTime参数设置)执行一次Minor GC,如果这个时间段内GC没有发生,那么就继续进行下一阶段(Remark);如果时间段内触发了Minor GC,则可能会执行一些优化
我们可以通过日志观察一次完整的CMS GC过程
1 | -XX:+UseConcMarkSweepGC |
50.201: [GC (CMS Initial Mark) [1 CMS-initial-mark: 47452K(174784K)] 349898K(489344K), 0.0289564 secs] [Times: user=0.22 sys=0.00, real=0.03 secs]
50.230: [CMS-concurrent-mark-start]
50.265: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.07 sys=0.00, real=0.03 secs]
50.265: [CMS-concurrent-preclean-start]
50.268: [CMS-concurrent-preclean: 0.003/0.003 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
50.268: [CMS-concurrent-abortable-preclean-start] CMS: abort preclean due to time 55.290: [CMS-concurrent-abortable-preclean: 1.618/5.022 secs] [Times: user=1.66 sys=0.02, real=5.02 secs]
55.290: [GC (CMS Final Remark) [YG occupancy: 302446 K (314560 K)]55.290: [Rescan (parallel) , 0.0252109 secs]55.315: [weak refs processing, 0.0000131 secs]55.315: [class unloading, 0.0122450 secs]55.327: [scrub symbol table, 0.0103126 secs]55.338: [scrub string table, 0.0007051 secs][1 CMS-remark: 47452K(174784K)] 349898K(489344K), 0.0503070 secs] [Times: user=0.22 sys=0.00, real=0.05 secs]
55.340: [CMS-concurrent-sweep-start]
55.356: [CMS-concurrent-sweep: 0.016/0.016 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
55.356: [CMS-concurrent-reset-start]
55.357: [CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
G1
G1(Garbage First)收集器是HotSpot JVM最新的垃圾收集器,它最大的特点就是将堆内存划分成多个连续的区域(region),每个区域大小相等。因此在G1中新生代与老年代都是由若干个Region组成(不需要连续)。Region的大小是可以重新设置的。
G1的优点:可以非常精确地控制停顿;老年代采用标记-压缩算法,避免了内存碎片的问题。
G1会在内部维护一个优先列表,通过一个合理的模型,计算出每个Region的收集成本和收益期望并量化,这样每次进行GC时,G1总是会选择最适合的Region(通常垃圾比较多)进行回收,使GC时间满足设置的条件。
G1的新生代收集类似于ParNew,同样是基于复制的算法(英文叫evacuation),存活的对象会被移至Survivor区,空间不够则一些对象需要晋升至老年代。新生代收集同样会有STW。
每次GC中,Eden区和Survivor区的大小都会被重新计算来提供给下一次Minor GC(根据内部记录的一些信息以及设置的期望停顿时间)。

G1通过引入Remembered Set来避免全堆扫描。Remembered Set用于跟踪对象引用。G1中每个Region都有对应的Remembered Set。当JVM发现内部的一个引用关系需要更新(对Reference类型进行写操作),则立即产生一个Write Barrier中断这个写操作,并检查Reference引用的对象是否处于不同的Region之间(用分代的思想,就是新生代和老年代之间的引用)。如果是,则通过CardTable通知G1,G1根据CardTable把相关引用信息记录到被引用对象所属的Region的Remembered Set中,并将Remembered Set加入GC Root。这样,在G1进行根节点枚举时就可以扫描到该对象而不会出现遗漏。
G1老年代GC过程
Initial Mark(STW)
This is a stop the world event. With G1, it is piggybacked on a normal young GC. Mark survivor regions (root regions) which may have references to objects in old generation.
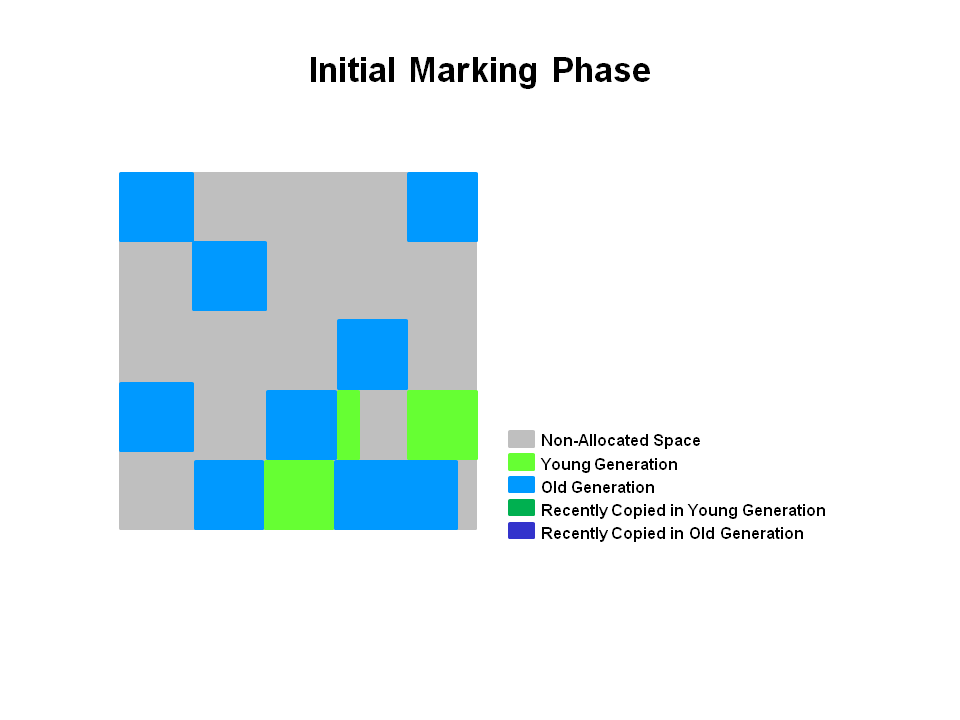
Root Region Scanning
Scan survivor regions for references into the old generation. This happens while the application continues to run. The phase must be completed before a young GC can occur.
Concurrent Marking
Find live objects over the entire heap. This happens while the application is running. This phase can be interrupted by young generation garbage collections.
Remark(STW)
Cleanup(STW and concurrent)
Copying(STW)
G1老年代收集的几个要点:
Concurrent Marking Phase
Liveness information is calculated concurrently while the application is running.
This liveness information identifies which regions will be best to reclaim during an evacuation pause.
There is no sweeping phase like in CMS.
Remark Phase
Uses the Snapshot-at-the-Beginning (SATB) algorithm which is much faster then what was used with CMS.
Completely empty regions are reclaimed.
Copying/Cleanup Phase
Young generation and old generation are reclaimed at the same time.
Old generation regions are selected based on their liveness.
分析日志
可以清晰地观察G1的收集阶段1
2
3
4-XX:+UseG1GC
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
5.891: [GC pause (G1 Evacuation Pause) (young), 0.0288342 secs]
[Parallel Time: 22.9 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 5891.4, Avg: 5891.4, Max: 5891.5, Diff: 0.1]
[Ext Root Scanning (ms): Min: 1.1, Avg: 3.0, Max: 13.6, Diff: 12.5, Sum: 24.1]
[Update RS (ms): Min: 0.0, Avg: 0.3, Max: 0.7, Diff: 0.7, Sum: 2.1]
[Processed Buffers: Min: 0, Avg: 3.9, Max: 10, Diff: 10, Sum: 31]
[Scan RS (ms): Min: 0.0, Avg: 0.5, Max: 0.8, Diff: 0.7, Sum: 3.8]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.4, Diff: 0.4, Sum: 1.0]
[Object Copy (ms): Min: 3.3, Avg: 13.8, Max: 20.2, Diff: 16.9, Sum: 110.5]
[Termination (ms): Min: 0.0, Avg: 5.1, Max: 5.8, Diff: 5.8, Sum: 40.8]
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 22.8, Avg: 22.8, Max: 22.8, Diff: 0.1, Sum: 182.4]
[GC Worker End (ms): Min: 5914.2, Avg: 5914.2, Max: 5914.3, Diff: 0.0]
[Code Root Fixup: 0.2 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.3 ms]
[Other: 5.4 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 4.8 ms]
[Ref Enq: 0.1 ms]
[Redirty Cards: 0.2 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.2 ms]
[Eden: 251.0M(251.0M)->0.0B(273.0M) Survivors: 14.0M->34.0M Heap: 286.6M(512.0M)->58.6M(512.0M)]
[Times: user=0.18 sys=0.00, real=0.02 secs]
8.119: [GC pause (Metadata GC Threshold) (young) (initial-mark), 0.0240591 secs]
[Parallel Time: 14.9 ms, GC Workers: 8]
[GC Worker Start (ms): Min: 8119.1, Avg: 8119.4, Max: 8120.3, Diff: 1.1]
[Ext Root Scanning (ms): Min: 0.5, Avg: 2.3, Max: 9.7, Diff: 9.2, Sum: 18.2]
[Update RS (ms): Min: 0.0, Avg: 0.2, Max: 0.4, Diff: 0.4, Sum: 1.2]
[Processed Buffers: Min: 0, Avg: 2.5, Max: 6, Diff: 6, Sum: 20]
[Scan RS (ms): Min: 0.0, Avg: 0.7, Max: 0.9, Diff: 0.9, Sum: 5.4]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.2, Max: 0.4, Diff: 0.4, Sum: 1.3]
[Object Copy (ms): Min: 4.9, Avg: 11.1, Max: 12.4, Diff: 7.5, Sum: 89.2]
[Termination (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.7]
[Termination Attempts: Min: 1, Avg: 20.9, Max: 31, Diff: 30, Sum: 167]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
[GC Worker Total (ms): Min: 13.7, Avg: 14.5, Max: 14.8, Diff: 1.1, Sum: 116.1]
[GC Worker End (ms): Min: 8133.9, Avg: 8134.0, Max: 8134.0, Diff: 0.0]
[Code Root Fixup: 0.3 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.2 ms]
[Other: 8.6 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 8.2 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.1 ms]
[Eden: 159.0M(273.0M)->0.0B(291.0M) Survivors: 34.0M->16.0M Heap: 219.6M(512.0M)->68.1M(512.0M)]
[Times: user=0.11 sys=0.00, real=0.03 secs]
8.143: [GC concurrent-root-region-scan-start]
8.151: [GC concurrent-root-region-scan-end, 0.0081611 secs]
8.151: [GC concurrent-mark-start]
8.191: [GC concurrent-mark-end, 0.0399863 secs]
8.192: [GC remark 8.192: [Finalize Marking, 0.0005544 secs] 8.192: [GC ref-proc, 0.0002680 secs] 8.192: [Unloading, 0.0068146 secs], 0.0079309 secs]
[Times: user=0.04 sys=0.00, real=0.00 secs]
8.200: [GC cleanup 74M->66M(512M), 0.0005223 secs]
[Times: user=0.00 sys=0.00, real=0.00 secs]
8.201: [GC concurrent-cleanup-start]
8.201: [GC concurrent-cleanup-end, 0.0000154 secs]
目前来说,大内存对G1支持的较好,其余的情况有待观察。是否将GC替换为G1还有待实验(何况很多公司还在用JDK 1.7)。有消息称JDK 9会把G1作为默认的GC。
目前所有的新生代gc都是需要STW的
Serial:单线程STW,复制算法
ParNew:多线程并行STW,复制算法
Parallel Scavange:多线程并行STW,吞吐量优先,复制算法
G1:多线程并发,可以精确控制STW时间,整理算法
Minor GC: 从young sapce回收内存
Major GC: 从tenured回收
Full GC: 从整个heap中回收
有一点需要注意,通常Major GC都是由Minor GC引起的,所以通常意味着并不能严格区分这几者。
GC root: gc标记算法中对象树的根,一般分为:
CMS算法:ParNew(Young)GC + CMS(Old)GC (piggyback on ParNew的结果/老生代存活下来的object只做记录,不做compaction)+ Full GC for CMS算法(应对核心的CMS GC某些时候的不赶趟,开销很大);
CMS GC的initial marking的触发条件是老生代使用比率超过某值;
Full GC定义是相对明确的,就是针对整个新生代、老生代、元空间(metaspace,java8以上版本取代perm gen)的全局范围的GC;
Minor GC和Major GC是俗称,在Hotspot JVM实现的Serial GC, Parallel GC, CMS, G1 GC中大致可以对应到某个Young GC和Old GC算法组合;
最重要是搞明白上述Hotspot JVM实现中几种GC算法组合到底包含了什么。
Serial GC算法:Serial Young GC + Serial Old GC (敲黑板!敲黑板!敲黑板!实际上它是全局范围的Full GC);
Parallel GC算法:Parallel Young GC + 非并行的PS MarkSweep GC / 并行的Parallel Old GC(敲黑板!敲黑板!敲黑板!这俩实际上也是全局范围的Full GC),选PS MarkSweep GC 还是 Parallel Old GC 由参数UseParallelOldGC来控制;
CMS算法:ParNew(Young)GC + CMS(Old)GC (piggyback on ParNew的结果/老生代存活下来的object只做记录,不做compaction)+ Full GC for CMS算法(应对核心的CMS GC某些时候的不赶趟,开销很大);
G1 GC:Young GC + mixed GC(新生代,再加上部分老生代)+ Full GC for G1 GC算法(应对G1 GC算法某些时候的不赶趟,开销很大)
总结
Serial:单线程STW,复制算法
ParNew:多线程并行STW,复制算法
Parallel Scavange:多线程并行STW,吞吐量优先,复制算法
G1:多线程并发,可以精确控制STW时间,整理算法

