
Dubbo是Alibaba开源的分布式服务框架,我们可以非常容易地通过Dubbo来构建分布式服务,并根据自己实际业务应用场景来选择合适的集群容错模式,这个对于很多应用都是迫切希望的,只需要通过简单的配置就能够实现分布式服务调用,也就是说服务提供方(Provider)发布的服务可以天然就是集群服务,比如,在实时性要求很高的应用场景下,可能希望来自消费方(Consumer)的调用响应时间最短,只需要选择Dubbo的Forking Cluster模式配置,就可以对一个调用请求并行发送到多台对等的提供方(Provider)服务所在的节点上,只选择最快一个返回响应的,然后将调用结果返回给服务消费方(Consumer),显然这种方式是以冗余服务为基础的,需要消耗更多的资源,但是能够满足高实时应用的需求。
Dubbo服务集群容错
假设我们使用的是单机模式的Dubbo服务,如果在服务提供方(Provider)发布服务以后,服务消费方(Consumer)发出一次调用请求,恰好这次由于网络问题调用失败,那么我们可以配置服务消费方重试策略,可能消费方第二次重试调用是成功的(重试策略只需要配置即可,重试过程是透明的);但是,如果服务提供方发布服务所在的节点发生故障,那么消费方再怎么重试调用都是失败的,所以我们需要采用集群容错模式,这样如果单个服务节点因故障无法提供服务,还可以根据配置的集群容错模式,调用其他可用的服务节点,这就提高了服务的可用性。
首先,根据Dubbo文档,我们引用文档提供的一个架构图以及各组件关系说明,如下所示:
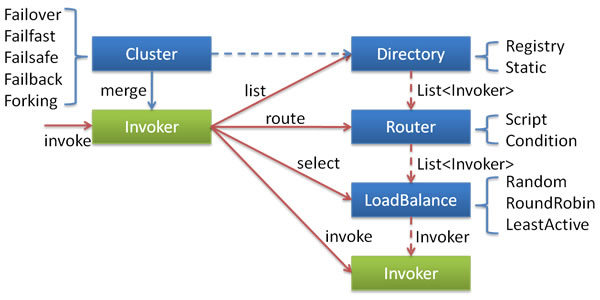
上述各个组件之间的关系(引自Dubbo文档)说明如下:
这里的Invoker是Provider的一个可调用Service的抽象,Invoker封装了Provider地址及Service接口信息。
Directory代表多个Invoker,可以把它看成List,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更。
Cluster将Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
Router负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等。
LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
我们也简单说明目前Dubbo支持的集群容错模式,每种模式适应特定的应用场景,可以根据实际需要进行选择。Dubbo内置支持如下6种集群模式:
Failover Cluster模式
配置值为failover。这种模式是Dubbo集群容错默认的模式选择,调用失败时,会自动切换,重新尝试调用其他节点上可用的服务。对于一些幂等性操作可以使用该模式,如读操作,因为每次调用的副作用是相同的,所以可以选择自动切换并重试调用,对调用者完全透明。可以看到,如果重试调用必然会带来响应端的延迟,如果出现大量的重试调用,可能说明我们的服务提供方发布的服务有问题,如网络延迟严重、硬件设备需要升级、程序算法非常耗时,等等,这就需要仔细检测排查了。
例如,可以这样显式指定Failover模式,或者不配置则默认开启Failover模式,配置示例如下:
1 | <dubbo:service interface="org.shirdrn.dubbo.api.ChatRoomOnlineUserCounterService" version="1.0.0" cluster="failover" retries="2" timeout="100" ref="chatRoomOnlineUserCounterService" protocol="dubbo" > |
上述配置使用Failover Cluster模式,如果调用失败一次,可以再次重试2次调用,服务级别调用超时时间为100ms,调用方法queryRoomUserCount的超时时间为80ms,允许重试2次,最坏情况调用花费时间160ms。如果该服务接口org.shirdrn.dubbo.api.ChatRoomOnlineUserCounterService还有其他的方法可供调用,则其他方法没有显式配置则会继承使用dubbo:service配置的属性值。
Failfast Cluster模式
配置值为failfast。这种模式称为快速失败模式,调用只执行一次,失败则立即报错。这种模式适用于非幂等性操作,每次调用的副作用是不同的,如写操作,比如交易系统我们要下订单,如果一次失败就应该让它失败,通常由服务消费方控制是否重新发起下订单操作请求(另一个新的订单)。
Failsafe Cluster模式
配置值为failsafe。失败安全模式,如果调用失败, 则直接忽略失败的调用,而是要记录下失败的调用到日志文件,以便后续审计。
Failback Cluster模式
配置值为failback。失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
Forking Cluster模式
配置值为forking。并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。
Broadcast Cluster模式
配置值为broadcast。广播调用所有提供者,逐个调用,任意一台报错则报错(2.1.0开始支持)。通常用于通知所有提供者更新缓存或日志等本地资源信息。
上面的6种模式都可以应用于生产环境,我们可以根据实际应用场景选择合适的集群容错模式。如果我们觉得Dubbo内置提供的几种集群容错模式都不能满足应用需要,也可以定制实现自己的集群容错模式,因为Dubbo框架给我提供的扩展的接口,只需要实现接口com.alibaba.dubbo.rpc.cluster.Cluster即可,接口定义如下所示:
1 | (FailoverCluster.NAME) |
关于如何实现一个自定义的集群容错模式,可以参考Dubbo源码中内置支持的汲取你容错模式的实现,6种模式对应的实现类如下所示:
1 | com.alibaba.dubbo.rpc.cluster.support.FailoverCluster |

